
“デザイン×アイデア×ITで すべての人を次の世界へ”をミッションとする株式会社ルクレ(以下、ルクレ)が、工事写真を自動で適切に仕分けるAI技術「仕分けAI」を開発というリリースニュースをおとどけします。
12億枚の工事写真を解析、1,500種類の自動仕分けに対応

1999年の『蔵衛門』サービス開始以来、26年間に蓄積した12億枚超の工事写真を解析し、約1,500種類の仕分けパターンを認識。
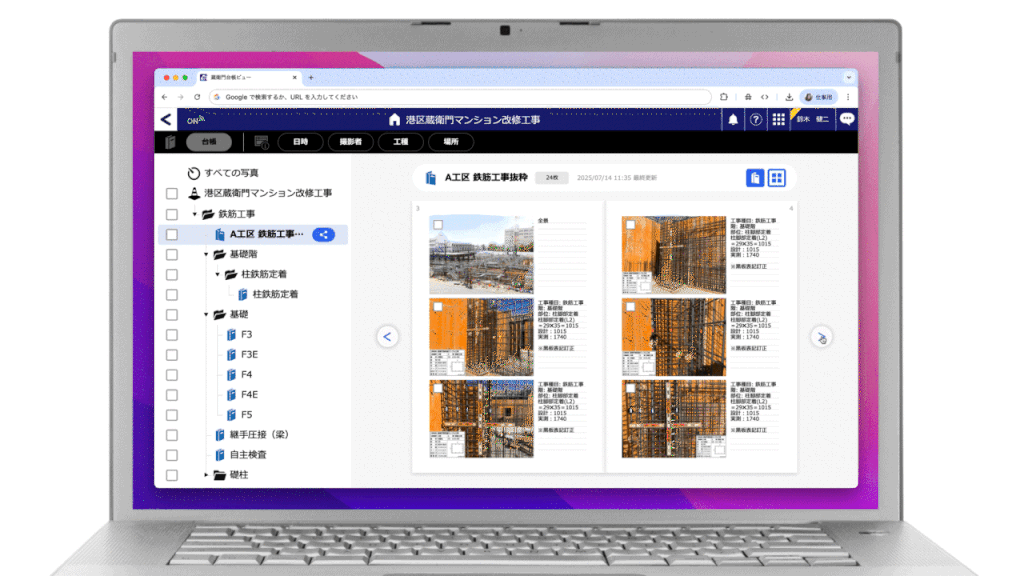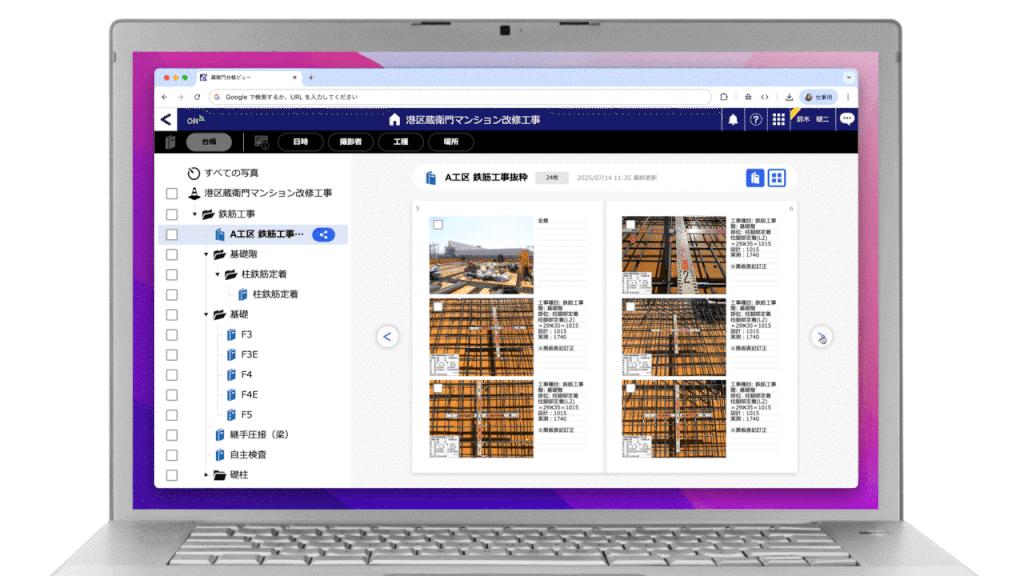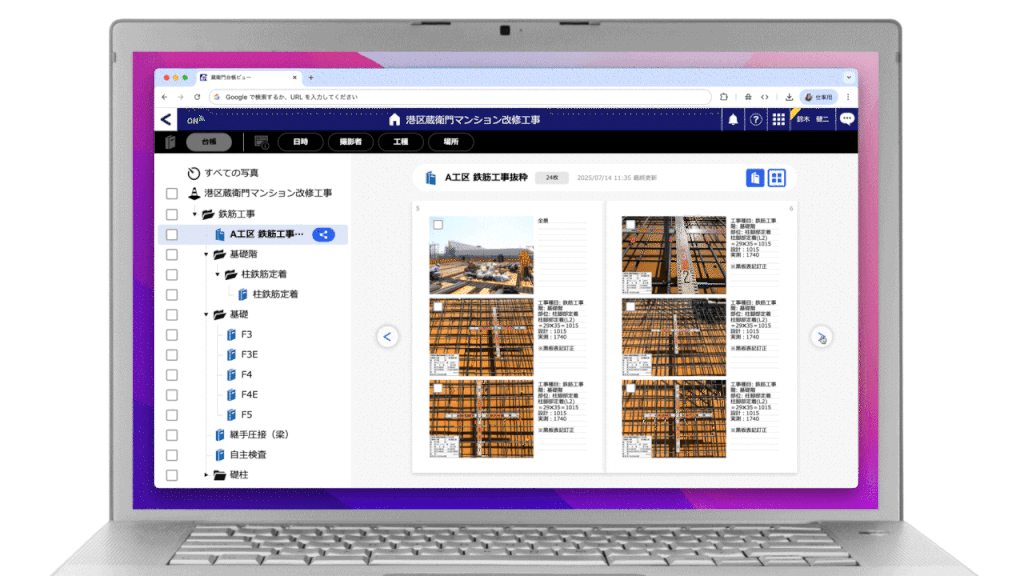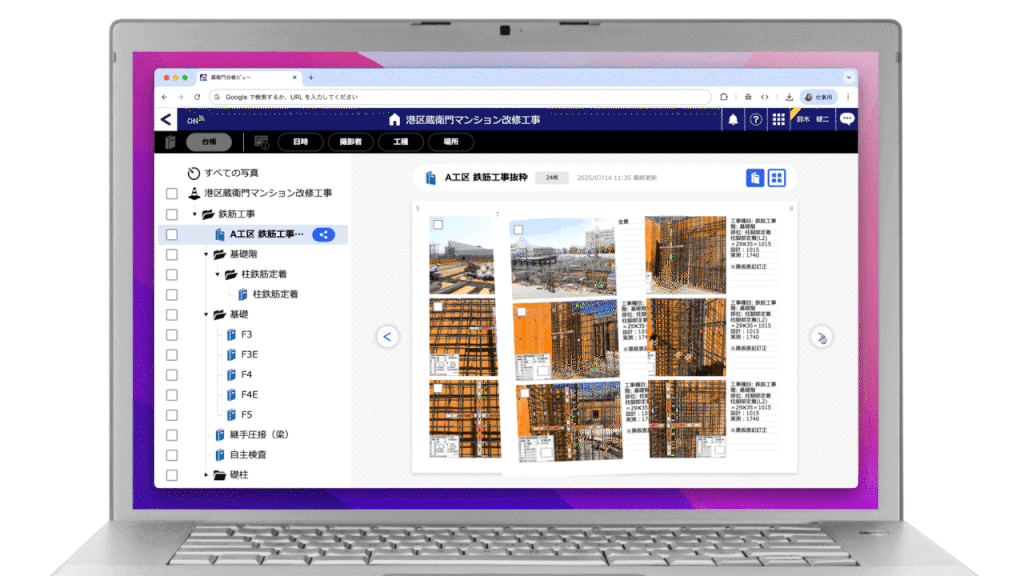
本技術を建設DXプラットフォーム『蔵衛門』の「台帳ビュー」機能に搭載し、最適な仕分け方法での写真整理・台帳作成を自動化します。
開発背景
建設業では、現場で働くノンデスクワーカーの深刻な人手不足と人件費の高騰を背景に、省人化・省力化が急務となっています。
しかし、現場では工事写真を小規模な工事でも数百枚、大規模な工事では数万枚も撮影。工種や場所など様々な項目で細かく写真を仕分けて台帳を作成し、発注者に提出することが必要なため、工事写真業務は依然として大きな負担となっています。
ルクレはこの課題を解決するため、26年間で蓄積した12億枚超の工事写真データを学習し、約1,500種類の仕分けパターンを生成。
写真を撮影すると自動で最適な仕分け方法を適用するAI技術を開発しました。本技術は、特許出願中です。
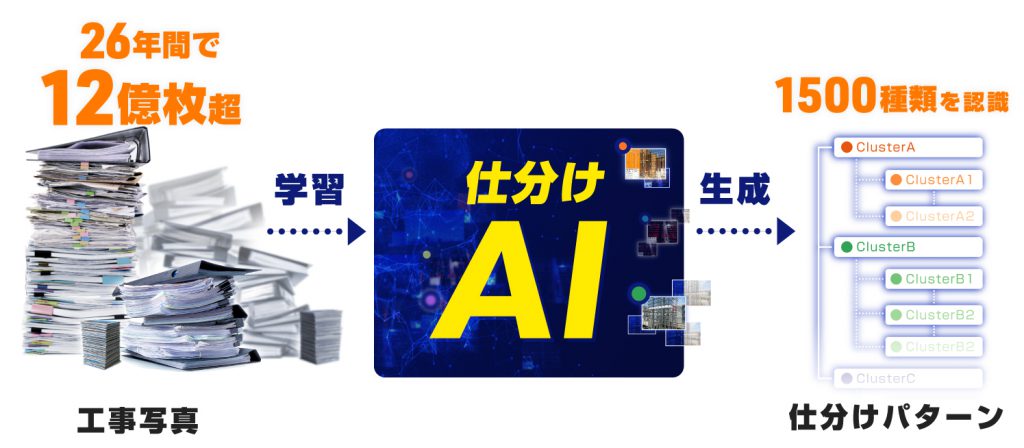
写真整理から解放される「仕分けAI」
「仕分けAI」は、電子小黒板の有無に関わらず、写真の仕分けから台帳作成までを自動化します。これによって経験に頼ることなく、誰でも悩まず写真整理ができ、仕分け作業が一瞬で完了します。
さらに、ユーザーの仕分け傾向を学習してパーソナライズされた仕分けにも対応します。
台帳は『蔵衛門』の「台帳ビュー」機能により工事関係者にクラウドで共有され、従来のように紙に印刷することなく、台帳の納品イメージをどこにいてもリアルタイムに確認することができます。
また、紙の台帳をそのままブラウザ上で再現した『蔵衛門』ならではの直感的なUI/UXで、誰もが迷わず利用できるサービスを実現しています。
■本技術のお問合せ先
蔵衛門お問合せ窓口:https://www.kuraemon.com/contact/
ルクレのAI技術
ルクレが、開発・提供してきたAI技術は下記の通りです。
・鉄筋コンクリート工事用の電子小黒板自動作成AI「e-Kokuban」(特許番号:6989884)
配筋リスト(PDF)から必要な豆図・テキスト項目を自動的に判断して電子小黒板を作成する技術。
・計測箇所の寸法を判定する工事写真管理AI(特許番号:7402458)
出来形管理等の工事写真から標尺を自動認識し、計測箇所の寸法を精度高く抽出・表示する技術。
・日本の子どもの写真に特化した顔認識AI「うちの子AI」
グローバルの大手クラウドサービスのエンジンでは解決できなかった日本の子どもの顔認識に特化したAI技術。スクール写真販売システム「みんなの写真屋さん」に搭載、他社システムにも提供。
『蔵衛門(くらえもん)』とは
1999年に発売した台帳作成ソフト『蔵衛門御用達』によって、写真管理に忙殺される現場監督の負担を軽減し、大手ゼネコンから小規模工務店にまで導入されています。
建設業界が業務効率化のために推奨する“電子小黒板”を、デジタルカメラに代わる電子小黒板タブレットとして『蔵衛門Pad』を2014年に発売。国土交通省が定めるNETIS(※)で最高評価(VE)を獲得しました。
建設業への残業規制を受け、現場監督ひとりに対する効率化ではなく、現場全体の効率化を推進するため、2022年4月からは、現場アプリ・共有クラウド・パソコンソフトをワンプラットフォーム化した『蔵衛門プレミアム』を提供開始。
施工管理で誰もが使う工事写真を軸にしているため、現場に無理なく浸透・定着させることが可能です。工事写真からはじめる建設DXプラットフォーム「蔵衛門」として施工に関わるすべての人の業務効率化を推進します。
※ NETIS(New Technology Information System:新技術情報提供システム)
※ 「蔵衛門」は、株式会社ルクレの登録商標です。
資料引用:ルクレ
おわりに
この一般的な「仕分けAI」がどのような内部構成で機能しているでしょうか。
すこし探ってみましょう。
① データ収集と前処理:AIの学習基盤の構築
AIが正確な仕分けを行うためには、高品質なデータが不可欠です。この段階では、AIが学習し、判断を下すための情報資産を構築します。
データ収集:
仕分けの対象となる多種多様なデータ(画像、テキスト、音声、センサーデータなど)を包括的に収集します。
データクレンジング:
収集されたデータに含まれるノイズ、欠損値、重複などを除去し、品質を向上させます。
これにより、AIの学習精度を最大化します。
特徴量エンジニアリング:
生データから、AIが判断基準とする特徴量を抽出・生成します。
例えば、画像データからは形状や色、テキストデータからはキーワードの出現頻度などが分析対象となります。高度なAIでは、この特徴量抽出を自動で行う機能も備わっています。
アノテーション(正解ラベル付与):
AIに学習させるため、各データがどのカテゴリに属するかの正解ラベルを付与します。これは手作業で行われる場合もあれば、既存のルールやデータを活用して自動化される場合もあります。
② 機械学習モデル:仕分けロジックの中核
このフェーズでは、収集・前処理されたデータに基づき、実際の仕分け判断を行うAIモデルを構築・最適化します。
モデル選択:
データの特性や仕分けタスクの複雑性に応じ、最適な機械学習モデルを選定します。
例えば、画像認識には畳み込みニューラルネットワーク(CNN)、テキスト分類にはTransformerモデル、構造化データには決定木モデルなどが選択肢となります。
モデル学習(トレーニング):
大量のラベル付きデータを用いて、モデルが最適な仕分けパターンを認識できるように学習させます。この過程で、モデル内部のパラメータが調整され、分類精度が向上します。
モデル評価:
学習済みのモデルが、未知のデータに対してどの程度の精度で仕分けできるかを評価します。誤分類率、適合率、再現率、F1スコアなどの客観的な指標を用いて、モデルの性能を検証します。
③ 推論・出力:実業務への適用
学習済みのAIモデルが、新たなデータを実際に仕分け、その結果を業務プロセスに組み込むための段階です。
入力インターフェース:
新たな仕分け対象データを受け入れるための連携口です。これにより、既存システムやユーザーからのデータをシームレスに取り込めます。
推論エンジン:
入力されたデータに対し、学習済みのAIモデルがリアルタイムで仕分け判断(予測)を実行します。
出力インターフェース:
推論結果(仕分けされたカテゴリ情報など)を、システム連携やユーザーへの情報提示という形で出力します。
確信度提示:
AIは仕分け結果に加え、その判断に対する確信度を併せて提示することが一般的です。
これにより、高確信度の自動処理と、低確信度の人間による確認といった柔軟な運用が可能となります。
④ フィードバックと再学習:継続的な性能向上
AIの仕分け精度を維持・向上させるためには、運用後の継続的な改善プロセスが不可欠です。
フィードバック収集:
AIによる仕分け結果に対するユーザーからの修正や評価をシステム的に収集します。
モデルの再学習(ファインチューニング):
収集されたフィードバックデータや新たなデータを取り込み、モデルを定期的に再学習(ファインチューニング)します。これにより、ビジネス環境の変化や新たなパターンにも対応できるよう、AIの性能を常に最適化します。
これらのモジュールが有機的に連携することで、一般的な「仕分けAI」は、企業の多様なデータ資産を効率的かつ高精度に分類・整理し、業務プロセスの自動化と高度化に貢献できるようになるのです。
豊富な学習データの12億枚の工事写真を解析したルクレAIは、こうした地道な4フェーズを経てリリースに至ったと推測できます。
参考・関連情報・お問い合わせなど
□株式会社ルクレ
リリースニュース https://lecre.jp/news/6166/